データ型#
from helper.python import print_subclasses
from helper.jupyter import row
import numpy as np
import polars as pl
Polarsは、データの効率的な管理と操作を可能にするため、多様なデータ型をサポートしています。この章では、Polarsで利用可能なデータ型を詳細に紹介し、各データ型の特性と用途について説明します。数値型、時系列型、ネスト型など、さまざまなデータ型がどのように構造化され、データ処理にどのように役立つかを理解することで、Polarsの強力なデータ処理機能を最大限に活用できるようになります。
データ型の継承木#
Polarsのデータ型は、非常に多様で柔軟性があります。次の継承木の構造と各データ型の詳細について説明します。この継承木は、各データ型がどのように構造化されているかを示し、各データ型の特性や用途を理解するのに役立ちます。NumericTypeやTemporalTypeのような主要なデータ型は、さらに細かいデータ型に分かれており、それぞれが特定のデータ処理ニーズに応じて最適化されています。NestedTypeは複雑なデータ構造をサポートし、BooleanやStringなどの基本的なデータ型も広範なデータ処理を可能にします。
print_subclasses(pl.DataType)
└──DataType
├──NumericType
│ ├──IntegerType
│ │ ├──SignedIntegerType
│ │ │ ├──Int8
│ │ │ ├──Int16
│ │ │ ├──Int32
│ │ │ ├──Int64
│ │ │ └──Int128
│ │ └──UnsignedIntegerType
│ │ ├──UInt8
│ │ ├──UInt16
│ │ ├──UInt32
│ │ └──UInt64
│ ├──FloatType
│ │ ├──Float32
│ │ └──Float64
│ └──Decimal
├──TemporalType
│ ├──Date
│ ├──Time
│ ├──Datetime
│ └──Duration
├──NestedType
│ ├──List
│ ├──Array
│ └──Struct
├──ObjectType
│ └──Object
├──Boolean
├──String
├──Binary
├──Categorical
├──Enum
├──Null
└──Unknown
数値型
NumericType: 数値型の基底クラス。整数型や浮動小数点型などの数値データを扱います。
IntegerType: 整数データを表すクラスの基底クラス。
SignedIntegerType: 符号付き整数データ(Int8、Int16、Int32、Int64)
UnsignedIntegerType: 符号なし整数データ(UInt8、UInt16、UInt32、UInt64)
FloatType: 浮動小数点データを表すクラスの基底クラス(Float32、Float64)
Decimal: 固定小数点数データを扱います。高精度の数値計算に使用されます。
時系列型
TemporalType: 時間に関連するデータ型の基底クラス。
Date: 日付データを扱います(例: 2024-07-18)。
Time: 時刻データを扱います(例: 12:34:56)。
Datetime: 日時データを扱います(例: 2024-07-18 12:34:56)。
Duration: 時間の期間を扱います(例: 5分、2時間)。
ネスト型
NestedType: ネスト構造を持つデータ型の基底クラス。
List: 要素のリストを扱います。リスト内の要素は同じデータ型でなければなりません。
Array: 固定長の配列を扱います。
Struct: 構造体データを扱います。異なるデータ型を持つ複数のフィールドを持つことができます。
その他のデータ型
Boolean: 真偽値データを扱います(TrueまたはFalse)。
String: 文字列データを扱います。
Binary: バイナリデータを扱います。
Categorical: カテゴリカルデータを扱います。効率的にカテゴリ値を管理します。
Enum: 列挙型データを扱います。
Object: 任意のPythonオブジェクトを扱います。特定のデータ型に適合しないデータを格納するために使用されます。
Null: NULL値を扱います。欠損値を示すために使用されます。
Unknown: 未知のデータ型を扱います。
データ型変換#
Cast#
Polarsは、データ型の変換を簡単に行うための便利な関数を提供しています。特に、cast() と shrink_dtype() の2つの関数は、データ型のキャストや縮小に使用されます。以下に、それぞれの関数について詳しく説明します。
df = pl.DataFrame(
{
"a": [3, 3, 3, 4],
"b": [4, 12, 6, 7],
"g": ['B', 'A', 'A', 'C']
}
)
df
| a | b | g |
|---|---|---|
| i64 | i64 | str |
| 3 | 4 | "B" |
| 3 | 12 | "A" |
| 3 | 6 | "A" |
| 4 | 7 | "C" |
cast()は、指定されたデータ型に列をキャストするために使用されます。この関数は、データの表現形式を変える際に非常に便利です。例えば、整数型の列を浮動小数点型に変換したり、文字列型の列を日付型に変換したりすることができます。
df.with_columns(
pl.col.a.cast(pl.UInt8),
pl.col.b.cast(pl.String)
)
| a | b | g |
|---|---|---|
| u8 | str | str |
| 3 | "4" | "B" |
| 3 | "12" | "A" |
| 3 | "6" | "A" |
| 4 | "7" | "C" |
shrink_dtype()は、データ型を必要最小限のサイズに縮小するために使用されます。例えば、Int64 型の列が実際には Int32 で十分な場合、この関数を使用してデータ型を自動的に縮小することができます。これにより、メモリ使用量を削減し、効率的なデータ管理が可能になります。
df.select(pl.all().shrink_dtype())
| a | b | g |
|---|---|---|
| i8 | i8 | str |
| 3 | 4 | "B" |
| 3 | 12 | "A" |
| 3 | 6 | "A" |
| 4 | 7 | "C" |
8bit や 16bit の整数において、符号付き型と無符号型の間で変換を行う場合は、cast() メソッドの wrap_numerical 引数を True に設定します。
df = pl.DataFrame(
[
pl.Series("A", [1, 2, -1, -2], dtype=pl.Int16),
pl.Series("B", [1, 2, 0xffff, 0xfffe], dtype=pl.UInt16)
]
)
df.select(
pl.col('A').cast(pl.UInt16, wrap_numerical=True),
pl.col('B').cast(pl.Int16, wrap_numerical=True),
)
| A | B |
|---|---|
| u16 | i16 |
| 1 | 1 |
| 2 | 2 |
| 65535 | -1 |
| 65534 | -2 |
データ型再定義#
cast()はデータの数値を変換しますが、NumPyの.view()のように、データのバイト表現をそのままにして別の型として解釈したい場合があります。そのような場合はreinterpret()を使用します。
Polarsの最新バージョンでは、Expr.reinterpret()にdtypeパラメータを指定することで、従来の符号付き/無符号整数の変換に加えて、同じバイトサイズの任意の数値型に再解釈できるようになりました。
次の例では、誤ってUInt64として保存されたデータをFloat64として再解釈します。
df_wrong = pl.DataFrame({"nums": [4837362400224322580, None, 4837362400224322584]}, schema={"nums": pl.UInt64})
df_fixed = df_wrong.select(pl.col("nums").reinterpret(dtype=pl.Float64))
row(df_wrong, df_fixed)
shape: (3, 1)
|
shape: (3, 1)
|
reinterpret()のsigned引数を使うと、符号付き整数と無符号整数の間で再解釈できます。signed=Falseで無符号整数に変換し、signed=Trueで符号付き整数に変換します。
また、reinterpret(dtype=...)を用いれば、整数と浮動小数点数の相互変換も可能です。ただし、変換元と変換先のデータ型は同じバイトサイズでなければなりません。例えば、Int32からInt64への再解釈はサイズが異なるためエラーになります。
次のコードでは、signed引数を使用した符号付き/無符号整数の変換を示しています。
df = pl.DataFrame(
[
pl.Series("A", [1, 2, -1, -2], dtype=pl.Int32),
pl.Series("B", [1, 2, 0xffffffff, 0xfffffffe], dtype=pl.UInt32)
]
)
df.with_columns(
pl.col('A').reinterpret(signed=False),
pl.col('B').reinterpret(signed=True)
)
| A | B |
|---|---|
| u32 | i32 |
| 1 | 1 |
| 2 | 2 |
| 4294967295 | -1 |
| 4294967294 | -2 |
バイナリ文字列から同じバイト数のデータ型に変換するには、bin.reinterpret()を使えます。dtype引数で変換後のデータ型を指定し、endianness引数でバイトオーダー(”big” または “little”)を指定できます。次の例では、バイナリデータが4バイトの符号なし整数(UInt32)に変換され、ビッグエンディアン(big-endian)として解釈されます。
df = pl.DataFrame({
'binary_column': [b'\x00\x00\x00\x01', b'\x00\x00\x00\x02', b'\x00\x00\x00\x03', b'\x00\x00@A']
})
df.select(pl.col('binary_column').bin.reinterpret(dtype=pl.UInt32, endianness="big"))
| binary_column |
|---|
| u32 |
| 1 |
| 2 |
| 3 |
| 16449 |
次に、reinterpret() を使用した興味深い実用例として、『Quake III Arena』のC言語ソースコードに登場する高速逆平方根(Fast inverse square root)の計算を見てみましょう。このコードでは魔法の数字 0x5f3759df を使って、浮動小数点数を整数として再解釈することで効率的に平方根の逆数を計算しています。
float Q_rsqrt( float number )
{
long i;
float x2, y;
const float threehalfs = 1.5F;
x2 = number * 0.5F;
y = number;
i = * ( long * ) &y; // 浮動小数点数のビットレベルハック
i = 0x5f3759df - ( i >> 1 ); // 魔法の数字
y = * ( float * ) &i;
y = y * ( threehalfs - ( x2 * y * y ) ); // 最初のニュートン反復
return y;
}
Polarsの reinterpret(dtype=...) を使えば、NumPyの .view() と同様のビットレベルハックをPolarsのエクスプレッションAPI内で実現できます。以下、NumPyでの実装とPolarsでの実装を比較します。
import numpy as np
number = np.linspace(0.1, 10, 100)
y = number.astype(np.float32) #❶
x2 = y * 0.5
i = y.view(np.int32) #❷
i[:] = 0x5F3759DF - (i >> 1) #❸
y = y * (1.5 - x2 * y * y) #❹
np.max(np.abs(1 / np.sqrt(number) - y)) #❺
np.float64(0.005045614041059743)
同じ計算をPolarsの reinterpret() を使って実装します。cast() は数値を変換しますが、reinterpret() はバイト表現をそのままにして型だけを変更する点がポイントです。
❶ NumPyの astype() に相当し、cast(pl.Float32) で値そのものを変換します。
❷ NumPyの .view(np.int32) に相当し、reinterpret(dtype=pl.Int32) で浮動小数点数のバイト列を整数として再解釈します。
❸ 整数として再解釈した値に対して // 2(右シフト相当)を計算し、魔法の数字 0x5F3759DF を引きます。その後、reinterpret(dtype=pl.Float32) で結果を再び浮動小数点数に戻します。Polarsの表現チェーン内で完結している点がNumPy版とは異なります。
❹ ニュートン反復を行い、平方根の逆数の近似値を計算します。
❺ 真の値と近似値の間の最大誤差を表示します。
import polars as pl
import numpy as np
# PolarsのreinterpretでQ_rsqrtを実装
number = np.linspace(0.1, 10, 100)
df = pl.DataFrame({"number": number})
result = (
df.with_columns(pl.col("number").cast(pl.Float32).alias("y")) #❶
.with_columns((pl.col("y") * 0.5).alias("x2"))
.with_columns(pl.col("y").reinterpret(dtype=pl.Int32).alias("i")) #❷
.with_columns(
(0x5F3759DF - pl.col("i") // 2) #❸
.reinterpret(dtype=pl.Float32)
.alias("y_approx")
)
.with_columns(
(pl.col("y_approx") * (1.5 - pl.col("x2") * pl.col("y_approx") * pl.col("y_approx")))
.alias("y_result") #❹
)
)
y_result = result["y_result"].to_numpy()
max_err = np.max(np.abs(1.0 / np.sqrt(number) - y_result))
print(f"最大誤差: {max_err}") #❺
result.head(5) # 結果の一部を表示
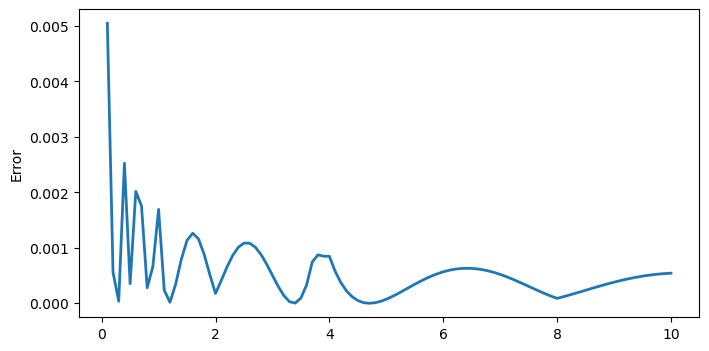
最大誤差: 0.005045614041059743
| number | y | x2 | i | y_approx | y_result |
|---|---|---|---|---|---|
| f64 | f32 | f32 | i32 | f32 | f32 |
| 0.1 | 0.1 | 0.05 | 1036831949 | 3.26486 | 3.157232 |
| 0.2 | 0.2 | 0.1 | 1045220557 | 2.26486 | 2.23551 |
| 0.3 | 0.3 | 0.15 | 1050253722 | 1.83243 | 1.825705 |
| 0.4 | 0.4 | 0.2 | 1053609165 | 1.63243 | 1.578616 |
| 0.5 | 0.5 | 0.25 | 1056964608 | 1.43243 | 1.41386 |
誤差の分布を可視化します。numberが小さいとき絶対誤差が大きくなりますが、このときの関数値も大きいため、相対誤差の変化はそれほど大きくありません。
import matplotlib.pyplot as plt
y_result = result["y_result"].to_numpy()
plt.figure(figsize=(8, 4))
plt.plot(number, 1 / np.sqrt(number) - y_result, lw=2)
plt.ylabel("Error");
文字列#
Polarsは文字列データの処理にも強力な機能を備えています。文字列処理関連の演算式関数はネーミングスペース.str の下にあります。
文字列の長さ#
str.len_chars(): 文字列のキャラクター数(文字数)を測定します。これは、文字列内に含まれる実際の文字の数を返します。たとえば、マルチバイト文字(日本語のような2バイト文字)も1文字としてカウントされます。str.len_bytes(): 文字列のバイト数を測定します。これは、各文字がエンコードされる際に占めるバイト数の合計を返します。マルチバイト文字は複数バイトとしてカウントされます。
df = pl.DataFrame({
"lib": ["pandas", "numpy", "polars", "図形"],
"ver": ["2.0", "1.1.4", "1.2.1", "4.0"]
})
df.select(
"lib",
len_char=pl.col("lib").str.len_chars(),
len_byte=pl.col("lib").str.len_bytes()
)
| lib | len_char | len_byte |
|---|---|---|
| str | u32 | u32 |
| "pandas" | 6 | 6 |
| "numpy" | 5 | 5 |
| "polars" | 6 | 6 |
| "図形" | 2 | 6 |
文字列の部分一致検索#
str.contains()、str.starts_with()、str.ends_with()などの関数で、特定の部分文字列が含まれるか、指定された文字列で始まるか、終わるかをチェックできます。
df.filter(pl.col.lib.str.starts_with("p"))
| lib | ver |
|---|---|
| str | str |
| "pandas" | "2.0" |
| "polars" | "1.2.1" |
df.filter(pl.col.ver.str.ends_with("0"))
| lib | ver |
|---|---|
| str | str |
| "pandas" | "2.0" |
| "図形" | "4.0" |
df.filter(pl.col.lib.str.contains('p'))
| lib | ver |
|---|---|
| str | str |
| "pandas" | "2.0" |
| "numpy" | "1.1.4" |
| "polars" | "1.2.1" |
.contains()には正規表現が使えます。次のコードは二つの点があるバージョンの行を取得します。
df.filter(pl.col.ver.str.contains("^\d+\.\d+\.\d+$"))
<>:1: SyntaxWarning: invalid escape sequence '\d'
<>:1: SyntaxWarning: invalid escape sequence '\d'
C:\Users\ruoyu\AppData\Local\Temp\ipykernel_2988\1031424121.py:1: SyntaxWarning: invalid escape sequence '\d'
df.filter(pl.col.ver.str.contains("^\d+\.\d+\.\d+$"))
| lib | ver |
|---|---|
| str | str |
| "numpy" | "1.1.4" |
| "polars" | "1.2.1" |
.str.contains_any() は特定の文字列やパターンのリストのいずれかが含まれているかを判定するために使用されます。このメソッドは、複数のキーワードが含まれているかどうかを一度にチェックしたい場合に非常に便利です。
df2 = pl.DataFrame({
"text": ["hello world", "data process library", "data science", "machine learning", "plot library"]
})
df2.filter(
pl.col("text").str.contains_any(["science", "machine"])
)
| text |
|---|
| str |
| "data science" |
| "machine learning" |
.str.contains_any() の引数には、演算式も使用できます。以下のプログラムは、text 列に含まれる単語の中で、出現頻度が上位2つの単語を含む行を抽出します。
expr = pl.col.text.str.split(' ').explode().value_counts(sort=True).head(2).struct.field('text')
row(df2.select(expr), df2.filter(pl.col.text.str.contains_any(expr)))
shape: (2, 1)
|
shape: (3, 1)
|
文字列の置換#
.str.replace(), .str.replace_all()で特定の部分文字列を置換します。
str.replace(): は最初に見つかったN個の一致のみを置換します。str.replace_all(): はすべての一致を置換します。
df2.select(pl.col.text.str.replace_all('data', 'DATA'))
| text |
|---|
| str |
| "hello world" |
| "DATA process library" |
| "DATA science" |
| "machine learning" |
| "plot library" |
文字列の分割#
文字列を特定の区切り文字で分割できます。
df2.with_columns([
pl.col("text").str.split(" ").alias("split")
])
| text | split |
|---|---|
| str | list[str] |
| "hello world" | ["hello", "world"] |
| "data process library" | ["data", "process", "library"] |
| "data science" | ["data", "science"] |
| "machine learning" | ["machine", "learning"] |
| "plot library" | ["plot", "library"] |
df2.with_columns([
pl.col("text").str.split_exact(" ", 1).alias("split_exact")
])
| text | split_exact |
|---|---|
| str | struct[2] |
| "hello world" | {"hello","world"} |
| "data process library" | {"data","process"} |
| "data science" | {"data","science"} |
| "machine learning" | {"machine","learning"} |
| "plot library" | {"plot","library"} |
文字列のトリミング#
文字列の前後の空白や特定の文字を除去します。
df3 = pl.DataFrame({
"text": [" hello ", " world", "polars ", "is ", " awesome"]
})
df3.with_columns([
pl.col("text").str.strip_chars(" ").alias("stripped"),
pl.col("text").str.strip_prefix(" ").alias("no_prefix"),
pl.col("text").str.strip_suffix(" ").alias("no_suffix")
])
| text | stripped | no_prefix | no_suffix |
|---|---|---|---|
| str | str | str | str |
| " hello " | "hello" | "hello " | " hello" |
| " world" | "world" | "world" | " world" |
| "polars " | "polars" | "polars " | "polars" |
| "is " | "is" | "is " | "is" |
| " awesome" | "awesome" | "awesome" | " awesome" |
str.strip_chars(): 両端の空白を削除。str.strip_prefix(): 左端の空白を削除。str.strip_suffix(): 右端の空白を削除。
文字列のパディング#
文字列の左右、または片方に特定の文字で埋めてパディングを行います。
df2.with_columns([
pl.col("text").str.pad_start(20, "-").alias("padded")
])
| text | padded |
|---|---|
| str | str |
| "hello world" | "---------hello world" |
| "data process library" | "data process library" |
| "data science" | "--------data science" |
| "machine learning" | "----machine learning" |
| "plot library" | "--------plot library" |
文字列の抽出#
文字列データからパターンにマッチした部分を抽出するには、str.extract、str.extract_all、str.extract_groups、str.extract_many などの関数を使用します。
str.extract(pattern, group_index) は、正規表現に基づいてマッチした 特定のキャプチャグループ を返します。
この関数には以下の2つの引数があります:
pattern: 正規表現パターン を指定します。文字列から特定の部分を抽出するために、()で囲んだ キャプチャグループ を用います。キャプチャグループは、マッチした部分を取得するための括弧で、複数のグループを作ることも可能です。その場合、それぞれのグループには 1, 2, 3… の番号が割り当てられます。group_index:キャプチャグループの番号 を指定します。正規表現内でどのグループを抽出するかを決定します。
以下のコードでは、pattern に2つのキャプチャグループを定義し、group_index を指定して アイテムA と アイテムB の数値を抽出します。
df = pl.DataFrame({
"text": ["Item A: 50, Item B: 30", "Item A: 70, Item B: 45"]
})
pattern = r'Item A: (\d+), Item B: (\d+)'
df.select(
pl.col("text").str.extract(pattern, 1).alias("A_value"),
pl.col("text").str.extract(pattern, 2).alias("B_value"),
)
| A_value | B_value |
|---|---|
| str | str |
| "50" | "30" |
| "70" | "45" |
str.extract_groups() は、正規表現の すべてのキャプチャグループ を抽出し、それらを 構造体(Struct)列 として返します。
グループ名が指定されていない場合、グループ番号(1, 2, 3, …)がフィールド名になります。
(
df.select(
pl.col('text').str.extract_groups(pattern).alias('values')
)
.unnest('values')
)
| 1 | 2 |
|---|---|
| str | str |
| "50" | "30" |
| "70" | "45" |
正規表現内で 名前付きキャプチャグループ (
?P<name>...)を使用した場合、その名前がフィールド名になります。
pattern_named = r'Item A: (?P<A_value>\d+), Item B: (?P<B_value>\d+)'
(
df.select(
pl.col("text").str.extract_groups(pattern_named).alias('values')
)
.unnest('values')
)
| A_value | B_value |
|---|---|
| str | str |
| "50" | "30" |
| "70" | "45" |
str.extract_all() は、正規表現に基づいてマッチしたすべての部分をリストとして返します。
df.select(
pl.col("text").str.extract_all(r'\d+').alias('values')
)
| values |
|---|
| list[str] |
| ["50", "30"] |
| ["70", "45"] |
Polarsには、re.split() のように正規表現を使って文字列を分割する関数が用意されていません。その代わりに、以下のコードでは extract_all() を用いて分割パターンを含むすべての部分を抽出し、list.eval() を使用して各文字列から分割パターンを削除することで、同様の機能を実装しています。
次のコードでは、
extract_all()を使って、分割パターン (and|after|or|then) を含むすべての部分を抽出します。list.eval()を使い、str.replace()で分割パターンを空文字 ("") に置き換えます。
こうすることで、Polars で re.split() のような文字列分割を実現できます。
df = pl.DataFrame(
{"text": [
"DOGandCATafterFISHorBIRDthenMOUSE",
"a or b or c"
]})
pattern = "and|after|or|then"
def split(expr, pattern):
return expr.str.extract_all(rf".*?({pattern}|$)").list.eval(pl.element().str.replace(pattern, ''))
df.select(pl.col('text').pipe(split, pattern)).get_column('text').to_list()
[['DOG', 'CAT', 'FISH', 'BIRD', 'MOUSE'], ['a ', ' b ', ' c']]
str.extract_many() は、Aho-Corasickアルゴリズムを使用して、文字列内から指定されたパターンに一致するすべての部分を抽出するための関数です。このメソッドは、正規表現ではなく、文字列リテラルのみに基づいてマッチングを行います。このメソッドは、文字列検索に対して非常に効率的であり、大量のデータセットでもパフォーマンスを発揮します。引数は以下のようです。
patterns: 検索する文字列パターンのリストを指定します。["apple", "banana", "orange"]のように、探したい特定の単語や文字列をリスト形式で与えます。ascii_case_insensitive: 大文字・小文字を区別しないマッチングを有効にするかどうかを指定します。overlapping: オーバーラップするマッチを許可するかどうかを指定します。Trueにすると、同じ文字列内で複数のパターンが重複している場合、それぞれを独立したマッチとして扱います。
df = pl.DataFrame({
"text": ["I like apples and bananas", "I prefer oranges and pineapples"]
})
# "apple"と"banana"を検索
df.select(
pl.col("text").str.extract_many(["apple", "banana"]).alias("matches")
)
| matches |
|---|
| list[str] |
| ["apple", "banana"] |
| ["apple"] |
EnumとCategorical#
Enum型(列挙型)は、特定の固定された値の集合から選択されるデータ型です。これは、データの一貫性を確保し、誤った値が入力されるのを防ぐのに役立ちます。Enum型を使用することで、プログラム内で定義された値以外の入力を防ぐことができ、データの整合性を維持することができます。
Categorical型(カテゴリカル型)は、有限個のカテゴリーを持つデータ型で、データの重複を避け、メモリ効率を向上させるために使用されます。Categorical型は、各カテゴリに整数のインデックスを割り当てることで、メモリ使用量を削減します。
Enumは事前に作成され、要素とその順番が固定されています。一方、Categoricalは事前作成の必要がなく、要素の順番はデータ内での出現順になります。
score = pl.Enum(['A', 'B', 'C', 'D'])
df = pl.DataFrame(
{
"a": [3, 3, 3, 4],
"b": [4, 12, 6, 7],
"g": ['B', 'A', 'A', 'C']
}
)
df2 = df.select(
pl.col.g.cast(score).alias('g_enum'),
pl.col.g.cast(pl.Categorical).alias('g_cat')
)
df2
| g_enum | g_cat |
|---|---|
| enum | cat |
| "B" | "B" |
| "A" | "A" |
| "A" | "A" |
| "C" | "C" |
to_physical()を使用すると、内部で保存されている番号を取得できます。次の結果では、g_enum の番号は score で定義された番号であり、g_catの番号は元の列の値が出現する順番に基づいています。
df2.select(pl.all().to_physical())
| g_enum | g_cat |
|---|---|
| u32 | u32 |
| 1 | 0 |
| 0 | 1 |
| 0 | 1 |
| 2 | 2 |
次のコードは、Categorical型の列で異なるコードが使用される場合の違いを示しています。異なるコードが使用される二つのCategorical列同士で計算を行うと、処理が遅くなる可能性があります。
df3 = pl.DataFrame(dict(
c1 = pl.Series(["Polar", "Panda", "Brown", "Brown", "Polar"], dtype=pl.Categorical),
c2 = pl.Series(["Panda", "Brown", "Brown", "Polar", "Polar"], dtype=pl.Categorical),
))
df3.with_columns(pl.all().to_physical().name.suffix('_code'))
| c1 | c2 | c1_code | c2_code |
|---|---|---|---|
| cat | cat | u32 | u32 |
| "Polar" | "Panda" | 0 | 0 |
| "Panda" | "Brown" | 1 | 1 |
| "Brown" | "Brown" | 2 | 1 |
| "Brown" | "Polar" | 2 | 2 |
| "Polar" | "Polar" | 0 | 2 |
次に、pl.StringCache()を使用して、同じコードが使われるCategorical列を作成します。
with pl.StringCache() as s:
df4 = pl.DataFrame(dict(
c1 = pl.Series(["Polar", "Panda", "Brown", "Brown", "Polar"], dtype=pl.Categorical),
c2 = pl.Series(["Panda", "Brown", "Brown", "Polar", "Polar"], dtype=pl.Categorical),
))
df4.with_columns(pl.all().to_physical().name.suffix('_code'))
| c1 | c2 | c1_code | c2_code |
|---|---|---|---|
| cat | cat | u32 | u32 |
| "Polar" | "Panda" | 0 | 1 |
| "Panda" | "Brown" | 1 | 2 |
| "Brown" | "Brown" | 2 | 2 |
| "Brown" | "Polar" | 2 | 0 |
| "Polar" | "Polar" | 0 | 0 |
DateTime#
ListとArray#
一つの要素に複数の値を保存する場合は、List 列または Array 列を使用します。Array 列では、各要素の長さが一定でなければなりませんが、List 列では要素の長さが異なっても問題ありません。Array 列と List 列の要素を処理するための式関数は、それぞれ array および list ネームスペース内にあります。
See also
次のコードでは、a_list と b_arr という列を持つ DataFrame を作成し、それぞれのデータ型を schema で pl.List(pl.Int8) と pl.Array(pl.Int8, 3) に定義します。List 列のデータ型は pl.List(element_dtype) で、Array 列のデータ型は pl.Array(element_dtype, length) で定義されます。element_dtype は要素のデータ型を、length は各配列の長さを表します。
df = pl.DataFrame(
dict(
a_list=[[1, 2], [3, 4], [5, 6, 7]],
b_arr=[[1, 2, 3], [3, 4, 5], [5, 6, 7]]
),
schema=dict(a_list=pl.List(pl.Int8), b_arr=pl.Array(pl.Int8, 3))
)
df
| a_list | b_arr |
|---|---|
| list[i8] | array[i8, 3] |
| [1, 2] | [1, 2, 3] |
| [3, 4] | [3, 4, 5] |
| [5, 6, 7] | [5, 6, 7] |
次のコードでは、list ネームスペース内の max()、mean()、len() を使用して、a_list 列の各リストの最大値、平均値、要素数を計算し、新しい列として追加します。 また、b_arr 列の各配列の最大値を arr.max() で計算します。arr ネームスペースは比較的新しく、バージョン 1.24.0 では arr.len() と arr.mean() はまだサポートされていません。
df.with_columns(
a_max=pl.col("a_list").list.max(),
a_mean=pl.col("a_list").list.mean(),
a_len=pl.col("a_list").list.len(),
b_max=pl.col("b_arr").arr.max(),
)
| a_list | b_arr | a_max | a_mean | a_len | b_max |
|---|---|---|---|---|---|
| list[i8] | array[i8, 3] | i8 | f64 | u32 | i8 |
| [1, 2] | [1, 2, 3] | 2 | 1.5 | 2 | 3 |
| [3, 4] | [3, 4, 5] | 4 | 3.5 | 2 | 5 |
| [5, 6, 7] | [5, 6, 7] | 7 | 6.0 | 3 | 7 |
getとgather#
list.get(index) または arr.get(index) を使用すると、指定した index の要素を取得できます。次のコードでは、a_list 列の各リストの最初の要素と最後の要素の合計を計算します。b_arr 列に対しても同様の処理を行います。
df.with_columns(
a_first_plus_last = pl.col('a_list').list.get(0) + pl.col('a_list').list.get(-1),
b_first_plus_last =pl.col('b_arr').arr.get(0) + pl.col('b_arr').arr.get(-1),
)
| a_list | b_arr | a_first_plus_last | b_first_plus_last |
|---|---|---|---|
| list[i8] | array[i8, 3] | i8 | i8 |
| [1, 2] | [1, 2, 3] | 3 | 4 |
| [3, 4] | [3, 4, 5] | 7 | 8 |
| [5, 6, 7] | [5, 6, 7] | 12 | 12 |
list.gather(indices) を使用すると、複数のインデックスを指定して要素を取得し、新しいリスト列に保存できます。null_on_oob 引数のデフォルト値は False で、この場合、範囲外のインデックスを指定するとエラーが発生します。一方、True に設定すると、範囲外のインデックスは Null で埋められます。次のコードは、リスト a_list の各要素に対して、インデックス [2, 1, 0] の順に要素を取得し、範囲外のインデックスがある場合は Null で埋める処理を行います。
df.select(
'a_list',
gather=pl.col('a_list').list.gather([2, 1, 0], null_on_oob=True)
)
| a_list | gather |
|---|---|
| list[i8] | list[i8] |
| [1, 2] | [null, 2, 1] |
| [3, 4] | [null, 4, 3] |
| [5, 6, 7] | [7, 6, 5] |
concat_list と concat_arr#
pl.concat_list() 関数は、指定した列や式の結果をリストとして結合するために使用されます。この関数を使用すると、複数の列の値を 1 つのリスト列にまとめることができます。一方、pl.concat_arr() は、複数の式の結果を配列として結合します。
df = pl.DataFrame(
{
"a": [3, 3, 3, 4],
"b": [4, 12, 6, 7],
"g": ['B', 'A', 'A', 'C']
}
)
df.with_columns(
pl.concat_list(['a', 'b', pl.col('a') + pl.col('b')]).alias('ab_list'),
pl.concat_arr(['a', 'b', pl.col('a') + pl.col('b')]).alias('ab_arr'),
)
| a | b | g | ab_list | ab_arr |
|---|---|---|---|---|
| i64 | i64 | str | list[i64] | array[i64, 3] |
| 3 | 4 | "B" | [3, 4, 7] | [3, 4, 7] |
| 3 | 12 | "A" | [3, 12, 15] | [3, 12, 15] |
| 3 | 6 | "A" | [3, 6, 9] | [3, 6, 9] |
| 4 | 7 | "C" | [4, 7, 11] | [4, 7, 11] |
pl.concat_list()で複数の列を一つのリスト列に変換した後、.list下のメソッドを使って様々な計算を行うことができます。例えば、次のプログラムでは、この方法で次の計算を行います。
A,C,E列の行毎の総和。行毎の総和を計算する場合は、pl.sum_horizontal()も使えます。行毎の中間値
df_numbers = pl.DataFrame(
np.random.randint(0, 10, size=(6, 5)), schema=list("ABCDE")
)
df_numbers.with_columns(
pl.concat_list('A', 'C', 'E').list.sum().alias('sum_ACE'),
pl.sum_horizontal(pl.col('A', 'C', 'E')).alias('sum_ACE2'),
pl.concat_list('*').list.median().alias('median_all')
)
| A | B | C | D | E | sum_ACE | sum_ACE2 | median_all |
|---|---|---|---|---|---|---|---|
| i32 | i32 | i32 | i32 | i32 | i32 | i32 | f64 |
| 6 | 1 | 9 | 9 | 8 | 23 | 23 | 8.0 |
| 2 | 6 | 8 | 4 | 1 | 11 | 11 | 4.0 |
| 5 | 8 | 0 | 6 | 5 | 10 | 10 | 5.0 |
| 8 | 1 | 5 | 7 | 3 | 16 | 16 | 5.0 |
| 5 | 8 | 8 | 6 | 9 | 22 | 22 | 8.0 |
| 7 | 0 | 2 | 8 | 1 | 10 | 10 | 2.0 |
reshape#
Expr.reshape()はnumpy.reshape()と似ています。1つの列の要素を指定した数で横向きに並べる関数です。以下の例では、reshape()を使ってデータフレームの列の形状を変更しています。
row(
df_numbers.select(pl.col('*').reshape((-1, 3))),
df_numbers.select(pl.col('*').reshape((-1, 2))),
)
shape: (2, 5)
|
shape: (3, 5)
|
implode と explode#
Expr.implode()は、式の出力を1つのリスト列に変換します。以下のプログラムは、各列の最初の3行のデータをリストとして保存します。
df = pl.DataFrame(dict(A=[1, 2, 3, 4], B=["X", "Y", "X", "Z"]))
df.select(pl.col('*').head(3).implode())
| A | B |
|---|---|
| list[i64] | list[str] |
| [1, 2, 3] | ["X", "Y", "X"] |
Expr.explode()は、リスト内の要素を縦に展開します。次のプログラムでは、リスト列valueの要素を縦に並べ、group列の各要素をExpr.repeat_by()を使ってvalueの各リストの長さ回繰り返します。
pl.col("group").repeat_by(pl.col("value").list.lengths())は、group列の各要素をvalue列の各リストの長さ回繰り返します。pl.col("value").explode()は、value列のリストを縦に展開します。
結果として、group列の各要素は対応するvalue列の要素に合わせて繰り返されます。
df = pl.DataFrame(dict(group=["B", "A", "A", "C"], value=[[3, 4], [1, 2, 6], [1], [2, 3]]))
df.select(
pl.col.group.repeat_by(pl.col.value.list.len()).explode(),
pl.col.value.list.explode()
)
| group | value |
|---|---|
| str | i64 |
| "B" | 3 |
| "B" | 4 |
| "A" | 1 |
| "A" | 2 |
| "A" | 6 |
| "A" | 1 |
| "C" | 2 |
| "C" | 3 |
DataFrame.explode()は、Expr.explode()と同じ処理を行いますが、他の列のデータを自動的に繰り返します。次のプログラムでは、リスト列valueの要素を縦に並べ、他の列(group列)のデータを自動的に繰り返します。
df.explode('value')
| group | value |
|---|---|
| str | i64 |
| "B" | 3 |
| "B" | 4 |
| "A" | 1 |
| "A" | 2 |
| "A" | 6 |
| "A" | 1 |
| "C" | 2 |
| "C" | 3 |
List列とArray列同士の変換#
list.to_array() と arr.to_list() を使用すると、List列とArray列同士の変換ができます。arr.to_list() はそのまま変換できますが、list.to_array() の場合、要素の長さを引数として渡す必要があり、List列の要素の長さが一致しない場合はエラーになります。
df = pl.DataFrame(
dict(
a=[[1, 2], [3, 4], [5, 6]],
b=[[1, 2, 3], [3, 4, 5], [5, 6, 7]]
),
schema=dict(a=pl.List(pl.Int8), b=pl.Array(pl.Int8, 3))
)
df.with_columns(
a_to_arr=pl.col('a').list.to_array(2),
b_to_list=pl.col('b').arr.to_list()
)
| a | b | a_to_arr | b_to_list |
|---|---|---|---|
| list[i8] | array[i8, 3] | array[i8, 2] | list[i8] |
| [1, 2] | [1, 2, 3] | [1, 2] | [1, 2, 3] |
| [3, 4] | [3, 4, 5] | [3, 4] | [3, 4, 5] |
| [5, 6] | [5, 6, 7] | [5, 6] | [5, 6, 7] |
長さがバラバラのList列をArray列に変換するには、次の方法で list.gather() を使用してNullを埋め値として長さを揃え、その後Array列に変換します。
df = pl.DataFrame(
dict(
a=[[1, 2], [3, 4], [5, 6, 7], [8, 9, 10, 11]],
),
schema=dict(a=pl.List(pl.Int8))
)
df.with_columns(
a_arr=pl.col('a').list.gather(pl.int_range(end=4), null_on_oob=True).list.to_array(4)
)
| a | a_arr |
|---|---|
| list[i8] | array[i8, 4] |
| [1, 2] | [1, 2, … null] |
| [3, 4] | [3, 4, … null] |
| [5, 6, 7] | [5, 6, … null] |
| [8, 9, … 11] | [8, 9, … 11] |
Struct列への変換#
list.to_struct()は、リスト列の各要素を構造化データ(構造体)に変換します。このメソッドでは、リスト内の各値を個別のフィールドとして持つ構造体に変換し、フィールド数は引数n_field_strategyにn基づいて決定されます。'max_width'は、最長のリストの長さに基づいてフィールド数を設定するために使用されます。fields引数でフィールド名を指定します。
df = pl.DataFrame(dict(values=[[1, 2], [2, 3, 4], [1, 10]]))
df2 = df.select(pl.col.values.list.to_struct(n_field_strategy='max_width', fields=["a", "b"]))
row(df, df2)
print(df2.schema)
shape: (3, 1)
|
shape: (3, 1)
|
Schema({'values': Struct({'a': Int64, 'b': Int64})})
リスト列同士の計算#
Polarsでは、リスト列同士、またはリスト列と数値列の間で算術演算を行うことができます。
リスト列同士の演算: 各行において、対応するリストの要素ごとに演算が行われます。
リスト列と数値列の演算: 数値列の値が各リストの全要素に適用されます。
以下は具体的な例です。このデータフレームでは、x列とy列の要素がリストで、各行のリストの長さは一致しています。また、z列は数値列です。
df = pl.DataFrame(dict(
x=[[1, 3, 3], [4, 5, 7, 8]],
y=[[10, 20, 30], [40, 50, 60, 80]],
z=[10, 20]
))
df.with_columns(
x_plus_y = pl.col('x') + pl.col('y'),
x_plus_z = pl.col('x') + pl.col('z'),
)
| x | y | z | x_plus_y | x_plus_z |
|---|---|---|---|---|
| list[i64] | list[i64] | i64 | list[i64] | list[i64] |
| [1, 3, 3] | [10, 20, 30] | 10 | [11, 23, 33] | [11, 13, 13] |
| [4, 5, … 8] | [40, 50, … 80] | 20 | [44, 55, … 88] | [24, 25, … 28] |
ビットのリストから整数に変換#
リスト型の列内の各リストの要素と、単一のリストの要素を対応させて計算するために、単一のリストを持つ Series を作成するか、またはリストを直接計算する演算式を使用します。以下は、ビットのリストを整数に変換するプログラムで、この計算方法について説明します。
このコードでは、df_bits に格納されたビットのリストを整数値に変換します。ビット列 [b7, b6, ..., b0] を b7 * 2**7 + b6 * 2**6 + ... + b0 * 2**0 のように計算し、対応する整数値を求めます。
❶事前に 2**i のリストを Series に変換し、それを bits の各要素と掛け算した後、.list.sum() で合計を求めます。
❷pl.int_range(7, -1, -1) を使って 2**i の列を生成し、それを implode() で単一のリストを持つ列に変換した後、bits と掛け算して合計を求めます。
df_bits = pl.DataFrame(dict(
bits=[
[0, 1, 1, 0, 1, 1, 0, 0],
[1, 0, 0, 1, 1, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1]
]
))
df_val1 = df_bits.select(
value=(pl.col('bits') * pl.Series(values=[[2**i for i in range(7, -1, -1)]])).list.sum() #❶
)
df_val2 = df_bits.select(
value=(pl.col('bits') * (2 ** pl.int_range(7, -1, -1)).implode()).list.sum() #❷
)
with pl.Config() as conf:
conf.set_fmt_table_cell_list_len(10)
row(df_bits, df_val1, df_val2)
shape: (3, 1)
|
shape: (3, 1)
|
shape: (3, 1)
|
次のように、各ビットのリストの長さが異なる場合、int_ranges() を用いて各リストの長さに対応する指数のリストを作成し、ビット列を整数に変換します。
pl.col('bits').list.len() - 1: 各リストの長さを取得し、最上位ビットの指数を決定します。pl.int_ranges(..., -1, -1): 各リストの長さに対応する2**iの指数部分のリストを作成します。.list.eval(2 ** pl.element()): 各要素を2**iに変換します。
df_bits = pl.DataFrame(dict(
bits=[
[0, 1, 1, 0, 1, 1, 0, 0],
[1, 0, 0, 1, 1, 0, 0],
[1, 1, 1, 1]
]
))
df_val = df_bits.select(
(
(
pl.col('bits') *
pl.int_ranges(pl.col('bits').list.len() - 1, -1, -1).list.eval(2 ** pl.element())
)
).list.sum()
)
with pl.Config() as conf:
conf.set_fmt_table_cell_list_len(10)
row(df_bits, df_val)
shape: (3, 1)
|
shape: (3, 1)
|
サポートされていない演算#
Polars 1.24.0時点では、リスト列間の演算として算術演算(加算、減算、乗算、除算など)はサポートされていますが、それ以外の演算(例: 比較演算や論理演算)はサポートされていません。そのため、次のコードはエラーになります。
%%capture_except
df.select(
pl.col('x') * 10 > pl.col('y')
)
InvalidOperationError: cannot perform '>' comparison between series 'x' of dtype: list[i64] and series 'y' of dtype: list[i64]
次の方法を使えば、リスト列の要素同士の計算が可能です。
with_row_index(): 各行に一意のインデックスを追加します。このインデックスは後でグループ化に使用されます。explode('x', 'y'):x列とy列のリストを展開して、各リストの要素を縦方向に並べます。これにより、リスト要素の対応が維持されます。group_by('index'): 行ごとの演算結果を元の形に戻すため、インデックス列を基準にデータをグループ化します。agg(): 各グループ内で演算を行います。ここでは、x列の要素を10倍し、y列の対応する要素と比較します。drop('index'): 最後にインデックス列を削除して不要な列を取り除きます。
(
df
.with_row_index()
.explode('x', 'y')
.group_by('index')
.agg(
pl.col('x') * 10 > pl.col('y')
)
.drop('index')
)
| x |
|---|
| list[bool] |
| [false, true, false] |
| [false, false, … false] |
本書のhelper.polarsモジュールをインポートすると、list_eval()メソッドがDataFrameクラスに追加されます。このメソッドは、リスト列を含むデータフレームに対して要素ごとの演算を簡潔に実行するためのラッパーとして機能します。
import helper.polars
df.list_eval(
(pl.col('x') * 10 > pl.col('y')).alias('flag')
)
| flag |
|---|
| list[bool] |
| [false, true, false] |
| [false, false, … false] |
構造体(struct)#
polarsの構造体列は、複数のフィールドを持つ複合データ型で、複数の異なる型のデータを1つの列にまとめて格納することができます。構造体列は、データを整理して、より複雑なデータ構造を表現するのに役立ちます。データフレームを作成する際に、Pythonの辞書のリストを構造体列に変換することができます。
df = pl.DataFrame({
"person": [
{"name": "John", "age": 30, "car": "ABC"},
{"name": "Alice", "age": 65, "car": "VOX"},
{"name": "Tom", "age": 25, "car": "ABC"},
{"name": "Bob", "age": 45, "car": "KTL"},
{"name": "Fun", "age": 18, "car": None},
],
"num": [1, 2, 3, 4, 5],
})
df
| person | num |
|---|---|
| struct[3] | i64 |
| {"John",30,"ABC"} | 1 |
| {"Alice",65,"VOX"} | 2 |
| {"Tom",25,"ABC"} | 3 |
| {"Bob",45,"KTL"} | 4 |
| {"Fun",18,null} | 5 |
フィールドと列の変換#
構造体列を処理する関数は、structネームスペースにあります。たとえば、.struct.field()メソッドを使用して、構造体列から複数のフィールドを個別の列として取り出すことができます。
df2 = df.select(
pl.col('person').struct.field('name', 'age')
)
df2
| name | age |
|---|---|
| str | i64 |
| "John" | 30 |
| "Alice" | 65 |
| "Tom" | 25 |
| "Bob" | 45 |
| "Fun" | 18 |
.struct.field()の逆の操作は、pl.struct()を使用することです。pl.struct()を使うことで、複数の列を構造体列に変換することができます。次のコードでは、nameとageの2つの列を構造体としてまとめ、personという名前の構造体列を作成しています。
df2.select(
pl.struct('name', 'age').alias('person')
)
| person |
|---|
| struct[2] |
| {"John",30} |
| {"Alice",65} |
| {"Tom",25} |
| {"Bob",45} |
| {"Fun",18} |
フィールドの演算式#
.struct.with_fields() メソッドを使うと、構造体列に対してフィールドの追加や変換ができます。演算式では、pl.col() の代わりに pl.field() を使ってフィールドを指定します。これにより、構造体内の特定のフィールドに対して操作を実行できます。
次の例では、person 列内の name フィールドの文字列を大文字に変換した新しい name_upper フィールドを追加し、car フィールドの null 値を "Mazda" に置き換えます。また、age フィールドと num 列の値を足し算して、新しい age フィールドを更新します。
df2 = df.select(
pl.col("person").struct.with_fields(
pl.field("name").str.to_uppercase().alias('name_upper'),
pl.field("car").fill_null("Mazda"),
pl.field("age") + pl.col("num")
)
)
df2
| person |
|---|
| struct[4] |
| {"John",31,"ABC","JOHN"} |
| {"Alice",67,"VOX","ALICE"} |
| {"Tom",28,"ABC","TOM"} |
| {"Bob",49,"KTL","BOB"} |
| {"Fun",23,"Mazda","FUN"} |
DataFrame.unnest()は構造体列を複数の列に展開することができます。
df2.unnest('person')
| name | age | car | name_upper |
|---|---|---|---|
| str | i64 | str | str |
| "John" | 31 | "ABC" | "JOHN" |
| "Alice" | 67 | "VOX" | "ALICE" |
| "Tom" | 28 | "ABC" | "TOM" |
| "Bob" | 49 | "KTL" | "BOB" |
| "Fun" | 23 | "Mazda" | "FUN" |
出力は構造体の演算式#
一部の演算式の出力は構造体になることがあります。例えば、value_count() は:
df_car_count = df2.select(pl.col("person").struct.field("car").value_counts())
print(df_car_count.schema)
df_car_count
Schema({'car': Struct({'car': String, 'count': UInt32})})
| car |
|---|
| struct[2] |
| {"Mazda",1} |
| {"KTL",1} |
| {"ABC",2} |
| {"VOX",1} |
List または Array 列への変換#
次の方法で、構造体列を List 列または Array 列に変換できます。
まず、
struct.field('*')を使って全フィールドを選択するか、フィールド名のリストを指定して一部のフィールドを選択します。各フィールドのデータ型が異なる場合は、必要に応じて
cast()を使い、最も上位のデータ型に変換します。concat_list()またはconcat_arr()を使用して、1 つの List 列または Array 列に変換します。
df = pl.DataFrame(dict(
point=[{"x":1.0, "y":2, "z":3}, {"x":4.0, "y":5, "z":6}]
))
df2 = df.with_columns(
point_list=pl.concat_list(pl.col('point').struct.field('*').cast(pl.Float64)),
point_list_2d=pl.concat_list(pl.col('point').struct.field('x', 'y').cast(pl.Float64)),
point_arr=pl.concat_arr(pl.col('point').struct.field('*').cast(pl.Float64)),
)
df2
| point | point_list | point_list_2d | point_arr |
|---|---|---|---|
| struct[3] | list[f64] | list[f64] | array[f64, 3] |
| {1.0,2,3} | [1.0, 2.0, 3.0] | [1.0, 2.0] | [1.0, 2.0, 3.0] |
| {4.0,5,6} | [4.0, 5.0, 6.0] | [4.0, 5.0] | [4.0, 5.0, 6.0] |
複数の列を一緒に処理#
複数の列を一緒に処理するには、構造体を利用すると便利です。たとえば、次のコードでは、AとB列の値が同じ行に対して、最初の行だけを残します。
df = pl.DataFrame(
dict(
A = [1, 2, 1, 2, 1, 2],
B = [2, 4, 2, 5, 2, 4],
C = [1, 2, 3, 4, 5, 6]
)
)
df.filter(
pl.struct('A', 'B').is_first_distinct()
)
| A | B | C |
|---|---|---|
| i64 | i64 | i64 |
| 1 | 2 | 1 |
| 2 | 4 | 2 |
| 2 | 5 | 4 |
上のコードは、DataFrame.unique()と同じ結果を得られます。
df.unique(['A', 'B'], maintain_order=True, keep='first')
| A | B | C |
|---|---|---|
| i64 | i64 | i64 |
| 1 | 2 | 1 |
| 2 | 4 | 2 |
| 2 | 5 | 4 |
pl.when().then().otherwise() で同じ条件に基づいて複数の演算式を計算する際は、次のように構造体を使うことでコードを短くできます。
次のコードでは、A列の値に基づいてBとC列の値を操作します。
A列の値は1の場合は、B列の値に10を加算し、C列の値に100を加算します。A列の値は1ではない場合は、B列から10を減算し、C列から100を減算します。
pl.struct()で複数の演算式を一つの構造体に纏め、最後に.struct.field()で構造体のフィールドを列に戻ります。
df.with_columns(
pl.when(pl.col('A') == 1)
.then(
pl.struct(
pl.col('B') + 10,
pl.col('C') + 100
)
)
.otherwise(
pl.struct(
pl.col('B') - 10,
pl.col('C') - 100
)
)
.struct.field('B', 'C')
)
| A | B | C |
|---|---|---|
| i64 | i64 | i64 |
| 1 | 12 | 101 |
| 2 | -6 | -98 |
| 1 | 12 | 103 |
| 2 | -5 | -96 |
| 1 | 12 | 105 |
| 2 | -6 | -94 |