プログラムの実行効率向上#
Pythonの動的特性はプログラムの開発を便利にしますが、プログラムの実行速度を大幅に低下させることもあります。特に計算集約型のプログラムでは、PythonプログラムとC言語プログラムの実行効率には数十倍から数百倍の差が生じることがあります。
そのため、Pythonで計算クラスのプログラムを開発する際には、通常、NumPyやSciPyなどのコンパイル型言語で書かれた拡張ライブラリを呼び出し、Python内で大量のループや数値計算を直接行うことを避けます。これらの既存のライブラリが計算要件を満たせない場合、より効率的な言語でコア計算部分を書き、それにPythonの呼び出しインターフェースを提供することで、効率的な開発と効率的な計算を同時に実現します。
しかし、C言語で直接拡張ライブラリを書くと、Pythonが提供するすべての利便性を失います:関数のパラメータを手動で解析する必要があり、オブジェクトの参照カウントを手動で管理し、大量のPython/C API関数を覚える必要があります。これらの困難さにより、開発者は実際の問題解決に集中することができません。
本章では、Julia集合の計算を最適化することで、CFFI、ctypes、Cython、Numbaなどのさまざまな拡張ライブラリを使用してプログラムの計算速度を向上させる方法を紹介します。本書の後続の章では、CFFI、Cython、Numbaの使用方法について詳しく説明します。読者が本章で紹介するさまざまな高速化方法を習得すれば、Pythonプログラムの実行効率を心配する必要はなくなります。
import numpy as np
import numba as nb
import cmath
import random
from matplotlib import pyplot as plt
Pythonの計算が遅い理由#
Pythonプログラムの実行効率に影響を与える主な理由は2つあります:
PythonオブジェクトはC言語のデータをラップしています。このラップにより、各オブジェクト内で実際にデータを保存するアドレスが連続していないため、CPUのキャッシュ最適化に不利です。NumPyが提供する
ndarray配列はこの問題を完璧に解決します。PythonプログラムはPython仮想マシンで実行されます。どんな小さな計算ステップでも、複数のPython/C API関数を呼び出す必要があります。そのため、ループ内で大量にPython関数を呼び出す必要がある場合、関数の呼び出しコストは数値計算部分よりも大きくなります。NumPyが提供する
ufunc関数は、C言語でループを実装することで計算効率の問題を解決します。
Pythonオブジェクト#
Python言語の動的特性により、Pythonでは整数でさえもオブジェクトとしてメモリに保存されます。これには、オブジェクトの型やガベージコレクション用の参照カウンタなどの情報を追加で保存する必要があります。以下のプログラムから、Pythonでは整数オブジェクトが28バイトを占有することがわかります。一方、コンパイル型言語では、16ビット、32ビット、64ビットなど、必要なタイプの整数を使用できます。
import sys
aint = 10000
sys.getsizeof(aint)
28
sys.getrefcount()を使用して、オブジェクトの参照カウントを確認できます。以下では、まずaintオブジェクトの参照カウントを表示し、次にリストalistを作成してaintを10回参照し、最後にdelキーワードを使用してalistを削除します。出力から、aintオブジェクトの参照カウントの変化を確認できます。この例から、Pythonのリストオブジェクトには他のオブジェクトの参照が保存されていることがわかります。そのため、整数リストでは、すべての整数のバイナリデータを実際に保存するメモリアドレスは連続していません。これは、CPUのキャッシュ最適化に不利です。
print(sys.getrefcount(aint))
alist = [aint] * 10
print(sys.getrefcount(aint))
del alist
print(sys.getrefcount(aint))
2
12
2
NumPyの章で紹介したように、NumPy配列を使用してデータを保存する場合、すべてのデータを一つの連続したメモリ領域に保存できます。ただし、その中の特定の要素をPythonで計算する必要がある場合、その要素をPythonオブジェクトにラップする必要があります。このプロセスはボクシング(boxing)と呼ばれ、その逆はアンボクシング(unboxing)と呼ばれます。
以下の例では、リストから取り出された要素はオブジェクトそのものであり、2回のインデックス操作で同じオブジェクトを取得します。一方、配列から要素を取得する場合、ボクシング操作が必要で、毎回新しいPythonオブジェクトが作成されます。Pythonではisキーワードを使用して、2つの参照が同じオブジェクトを指しているかどうかを判断します。各参照とオブジェクトのメモリ内の関係は次のグラフに示されています。Pythonは実際の数値計算を行う前に、さまざまな参照、ボクシング、アンボクシングなどの操作を完了する必要があります。これがPythonの数値計算速度が遅い理由の1つです。

import numpy as np
alist = [1000, 1001, 1002]
arr = np.array(alist)
a = alist[1]
b = alist[1]
c = arr[1]
d = arr[1]
print(a is b)
print(c is d)
True
False
Pythonインタプリタ#
PythonプログラムはPython仮想マシンで実行されます。Pythonはプログラムを実行する際、まずコンパイラを呼び出してソースコードをバイトコードにコンパイルし、次にインタプリタでそのバイトコードを実行します。Pythonインタプリタはスタック仮想マシンであり、スタックを使用して仮想マシンの状態を保存します。disモジュールを使用して、Python関数のバイトコードを表示できます。以下のプログラムは、hypot()のバイトコードを表示します。hypot()の計算を完了するために、仮想マシンは10個のバイトコードを実行する必要があります。LOAD_FASTとLOAD_CONSTはそれぞれローカル変数と定数オブジェクトをスタックにプッシュし、BINARY_POWERとBINARY_ADDはスタックの最上位の2つのオブジェクトに対してべき乗演算と加算演算を行い、その結果をスタックにプッシュします。
import dis
def hypot(a, b):
return (a**2 + b**2) ** 0.5
dis.dis(hypot)
4 RESUME 0
5 LOAD_FAST 0 (a)
LOAD_CONST 1 (2)
BINARY_OP 8 (**)
LOAD_FAST 1 (b)
LOAD_CONST 1 (2)
BINARY_OP 8 (**)
BINARY_OP 0 (+)
LOAD_CONST 2 (0.5)
BINARY_OP 8 (**)
RETURN_VALUE
バイトコードを実行する仮想マシンのC言語ソースプログラムはceval.cであり、各バイトコードコマンドに対応するC言語プログラムが含まれています。以下のリンクを使用してそのソースプログラムを確認できます。
以下に、LOAD_FASTとBINARY_ADDコマンドに対応するC言語プログラムを示します。各バイトコードコマンドは、C言語プログラムの一部を実行する必要があることがわかります。加算計算のコードでは、まず演算対象が文字列オブジェクトかどうかを判断し、もしそうであれば文字列連結関数unicode_concatenate()を呼び出し、そうでなければPyNumber_Add()関数を呼び出します。PyNumber_Add()の実行をさらに追跡すると、2つの浮動小数点数の合計を実際に計算するために多くのコードを実行する必要があることがわかります。
case TARGET(LOAD_FAST): {
PyObject *value = GETLOCAL(oparg);
if (value == NULL) {
format_exc_check_arg(tstate, PyExc_UnboundLocalError,
UNBOUNDLOCAL_ERROR_MSG,
PyTuple_GetItem(co->co_varnames, oparg));
goto error;
}
Py_INCREF(value);
PUSH(value);
FAST_DISPATCH();
}
case TARGET(BINARY_ADD): {
PyObject *right = POP();
PyObject *left = TOP();
PyObject *sum;
if (PyUnicode_CheckExact(left) &&
PyUnicode_CheckExact(right)) {
sum = unicode_concatenate(tstate, left, right, f, next_instr);
}
else {
sum = PyNumber_Add(left, right);
Py_DECREF(left);
}
Py_DECREF(right);
SET_TOP(sum);
if (sum == NULL)
goto error;
DISPATCH();
}
C言語コンパイラの設定#
プログラムの実行速度を向上させるためには、コンパイラを使用して効率的な計算プログラムをマシンコードにコンパイルする必要があります。本書では、cffi、Cython、Numbaの3つの拡張ライブラリを使用してプログラムの計算速度を向上させる方法を紹介します。まず、以下のcondaコマンドを使用して、cffi、Cython、Numbaなどの拡張ライブラリをインストールします。
conda install cython numba cffi
cffiまたはCythonを使用して拡張モジュールをコンパイルするためには、優先するC言語コンパイラを設定する必要があります。Pythonはdistutilsを使用して拡張ライブラリをコンパイルし、distutilsは3つの設定ファイルからコンパイルオプションを読み取ります。これらの設定ファイルは以下の通りで、優先順位が上がります。
distutilsモジュールのパスにあるdistutils.cfgファイル。ユーザーのホームディレクトリにある
pydistutils.cfgファイル。現在のパスにある
setup.cfgファイル。
以下のプログラムは、上記の3つのファイルのパスを表示し、parse_config_files()を呼び出して設定を読み込みます。出力から、buildコマンドのcompilerオプションがmingw32に設定されていることがわかります。この設定はsetup.cfgファイルから読み込まれます。以下はそのファイルの内容です:
[build]
compiler=mingw32
See also
niXman/mingw-builds-binaries
MinGW-W64のインストーラーでインストールした後、gcc.exe のあるフォルダーのパスを PATH 環境変数に追加してください。
from distutils.core import Distribution
dist = Distribution()
print(dist.find_config_files())
dist.parse_config_files()
dist.command_options
['setup.cfg']
{'build': {'compiler': ('setup.cfg', 'mingw32')},
'build_ext': {'compiler': ('setup.cfg', 'mingw32')}}
Julia集合の計算最適化#
Julia集合は、複素平面上でフラクタルを形成する点の集合です。以下の式を反復して得られます:
固定された複素数\(c\)に対して、ある複素数\(z_{0}\)を取ると、次のシーケンスが得られます:
このシーケンスは無限大に発散するか、ある範囲内にとどまり、ある値に収束する可能性があります。発散しない\(z_0\)値の集合をJulia集合と呼びます。ランダム逆反復アルゴリズムを使用して、Julia集合上の点を計算できます。その具体的なアルゴリズムは以下の通りで、\(z_n\)と\(c\)はどちらも複素数です。
\(z_{0} ={\frac {1+{\sqrt {1-4c}}}{2}}\)で初期化します。
\(z_{n} = \sqrt{z_{n-1} - c}\)を計算します。
二分の一の確率で\(z_{n}\)の符号を変更します。
\(z_{n}\)を保存し、ステップ2を繰り返します。
この反復アルゴリズムは、NumPyが提供するufuncでは実装できず、ループを使用して各反復の結果を計算する必要があります。以下のpy_julia_set()は上記の計算を実装しており、cmathはPython標準ライブラリで複素数計算を行うモジュールです。
import numpy as np
import cmath
import random
def py_julia_set(c, n):
z = (1 + cmath.sqrt(1 - 4 * c)) / 2
res = np.zeros(n, dtype=np.complex128)
for i in range(n):
z = cmath.sqrt(z - c)
if random.randint(0, 1):
z = -z
res[i] = z
return res
c = -0.512511498387847167 + 0.521295573094847167j
%timeit py_julia_set(c, 100000)
z = py_julia_set(c, 100000)
133 ms ± 7.51 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
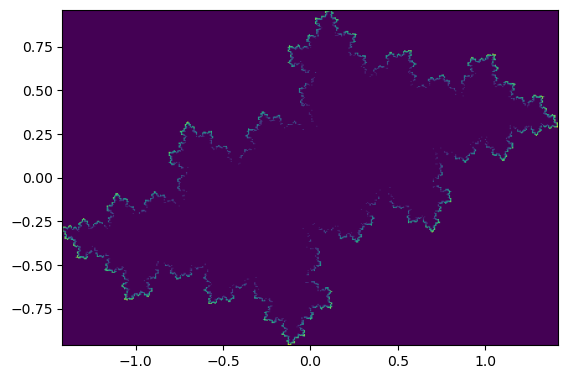
z は複素数の配列です。次のコードでは、z の実数部分と虚数部分を取り出し、histogram2d() を使用して 2 次元ヒストグラムを計算し、可視化します。
counts, xe, ye = np.histogram2d(z.real, z.imag, bins=400)
plt.imshow(np.log(counts.T + 1), extent=[xe[0], xe[-1], ye[0], ye[-1]]);
C言語関数の呼び出し#
以下のjulia.cファイルのjulia_set()は、py_julia_set()と同じ計算を実装しています。Pythonの外部関数呼び出しモジュールCFFIとctypesは複素数型の値をパラメータとしてサポートしていないため、ここではcrとciパラメータを使用して複素数\(c\)の実部と虚部をそれぞれ渡します。C言語関数内ではNumPy配列を作成できないため、ここでは複素数ポインタarrを使用して結果を出力し、nはその配列の長さです。
%%file julia.c
#include <complex.h>
#include <stdlib.h>
void julia_set(double cr, double ci, double complex * arr, int n)
{
int i;
double complex c;
double complex z;
c = cr + ci * I;
z = 0.0;
for(i=0; i<n; i++){
z = csqrt(z - c);
if(rand() & 0x01){
z = -z;
}
arr[i] = z;
}
}
Overwriting julia.c
以下のコマンドを呼び出すと、julia.cをダイナミックリンクライブラリjulia.dllにコンパイルし、その中で定義されたすべての関数をエクスポートできます。
!gcc -shared julia.c -o julia.dll
以下では、CFFIモジュールを使用してjulia.dll内のjulia_set()関数を呼び出します。❶まず、FFIオブジェクトを作成します。FFIは「Foreign Function Interface」(外部関数インターフェース)の略です。❷そのcdef()メソッドを呼び出して、ダイナミックリンクライブラリ内の外部関数の型を宣言します。CFFIモジュールは複素数型をサポートしていないため、arrポインタ型をdouble *として宣言します。ポインタ引数はアドレスを渡すため、関数呼び出し時に渡すポインタ型は重要ではありません。julia_set()内部では、arrのアドレス値を複素数ポインタとして処理します。❸dlopen()メソッドを呼び出してダイナミックリンクライブラリjulia.dllを開き、外部関数ライブラリを表すオブジェクトlibを取得します。これを使用して、cdef()で宣言されたすべての外部関数をPythonから呼び出すことができます。
❹外部関数を呼び出す際、CFFIは自動的にPythonのオブジェクトを対応するC言語の型データに変換します。例えば、floatオブジェクトはdouble型の数値に、intオブジェクトはint型の数値に変換されます。CFFIはNumPy配列を自動的に変換できないため、ここではffi.from_buffer()を呼び出してNumPy配列をそのデータストレージ領域へのポインタに変換します。ポインタの型は最初の引数で指定されます。NumPy配列を外部関数に渡す際、外部関数は配列のshapeやstridesなどの属性を取得できないことに注意する必要があります。lib.julia_set()に渡す配列が1次元で連続したストレージであることを確認する必要があります。
import cffi
ffi = cffi.FFI() #❶
ffi.cdef("void julia_set(double cr, double ci, double * arr, int n);") #❷
lib = ffi.dlopen("julia.dll") #❸
def cffi_julia_set(c, n):
res = np.zeros(n, dtype=np.complex128)
lib.julia_set(c.real, c.imag, ffi.from_buffer("double *", res), len(res)) #❹
return res
%timeit cffi_julia_set(c, 100000)
6.4 ms ± 213 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Pythonの標準ライブラリctypesを使用して外部関数を呼び出すこともできます。ctypesの使用手順はCFFIとは逆で、まずctypes.cdll.LoadLibrary()を使用してダイナミックリンクライブラリをロードし、次に外部関数のargtypesおよびrestype属性を使用してそのパラメータ型および戻り値型を設定します。NumPy配列のctypes.data_as()メソッドを使用して、ctypesのポインタオブジェクトに変換できます。
import ctypes
from ctypes import c_double, POINTER, c_int
dll = ctypes.cdll.LoadLibrary("julia.dll")
dll.julia_set.argtypes = [c_double, c_double, POINTER(c_double), c_int]
dll.julia_set.restype = None
res = np.zeros(10000, np.complex128)
dll.julia_set(c.real, c.imag, res.ctypes.data_as(POINTER(c_double)), len(res))
Cythonで計算速度向上#
Cythonは、C言語でPython拡張モジュールを書く負担を軽減するために開発されたプログラミング言語です。その構文は基本的にPythonと同じですが、C言語の関数を直接定義および呼び出したり、変数の型を定義したりする機能が追加されています。Cythonのコンパイラを使用して、CythonのソースプログラムをC言語のソースプログラムにコンパイルし、さらにC言語コンパイラを使用して拡張モジュールにコンパイルできます。Cythonプログラムは、C言語の計算速度を実現しつつ、Pythonのすべての動的特性を使用できるため、拡張ライブラリの作成が非常に便利になります。
Cython言語はPythonにcimport、cdef、extern fromなどのキーワードを追加し、wraparound、boundscheckなどのコンパイルディレクティブを使用してコンパイラの動作を制御できます。Cythonプログラムでは、Pythonオブジェクトを処理できるだけでなく、cdefを使用してC言語の型の変数や関数を定義できます。これにより、Python/C APIを呼び出す必要があったループを、C言語の関数のみを呼び出し、C言語のデータ型のみを処理するループにコンパイルできます。Cythonプログラムは、Pythonプログラムの柔軟性とC言語プログラムの高性能を同時に実現できます。
Notebookでは、%%cythonマジックコマンドを使用して拡張モジュールをコンパイルし、同時にそのモジュールで定義された関数をロードできます。このマジックコマンドは、%load_ext cythonを使用してロードする必要があります。以下のプログラムは%%cythonコマンドで始まり、Cythonプログラムであることを示しています。cy_julia_set()関数では、NumPyのzeros()を使用して配列を作成し、C言語関数ライブラリのcsqrt()およびrand()関数を呼び出しています。rand()はcimportキーワードを使用してlib.stdlibからロードし、csqrt()はC言語のヘッダファイル’complex.h’から直接ロードします。
Warning
cython/cython#5003
%%cython のバグに関する issue です。この issue が解決されるまで、次の方法で %%cython マジックコマンドをロードしてください。
import helper.cython
%load_ext helper.cython
import helper.cython
%load_ext helper.cython
%%cython --compile-args=-w
# distutils: define_macros=NPY_NO_DEPRECATED_API=NPY_1_7_API_VERSION
import numpy as np
cimport numpy as np
cimport cython
from libc.stdlib cimport rand
cdef extern from "complex.h":
double complex csqrt(double complex z)
@cython.wraparound(False)
@cython.boundscheck(False)
def cy_julia_set(double complex c, int n):
cdef double complex[::1] res
cdef double complex z
arr = np.zeros(n, np.complex128)
res = arr
z = 0
for i in range(n):
z = csqrt(z - c)
if rand() & 0x01:
z = -z
res[i] = z
return arr
%%cythonマジックコマンドは、Cythonモジュールをコンパイルした後、そのモジュール内のすべての関数を現在の実行環境にロードするため、cy_julia_set()を直接呼び出すことができます:
%timeit cy_julia_set(c, 100000)
5.7 ms ± 166 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
NumbaでJITコンパイル#
CFFIを使用してダイナミックリンクライブラリを呼び出す場合も、Cythonを使用して拡張モジュールをコンパイルする場合も、既存のPythonプログラムを変更し、C言語コンパイラを使用してコンパイルする必要があります。NumbaはLLVMコンパイルフレームワークを使用して実装されたジャストインタイムコンパイルライブラリで、Numbaを使用するとC言語コンパイラを必要とせずにPython関数を直接マシンコードにコンパイルしてプログラムの計算速度を向上させることができます。
以下では、numba.jit()を使用して前述のpy_julia_set()関数をジャストインタイムコンパイルしてnumba_julia_set()関数に変換します。numba_julia_set()を初めて呼び出す際、Numbaはpy_julia_set()をマシンコードにコンパイルします。ジャストインタイムコンパイルには時間がかかるため、numba_julia_set()の実行速度をテストするには、まずこの関数を一度実行してから、%timeitを使用してその実行時間を計算します。
import numba as nb
numba_julia_set = nb.jit(py_julia_set)
numba_julia_set(c, 10)
%timeit numba_julia_set(c, 100000)
5.41 ms ± 162 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
py_julia_set()はすべての反復点の座標を返しますが、反復回数が大きすぎると大量のメモリを消費します。この問題を解決するために、各座標付近の反復点の出現回数を返すことができます。以下のnumba_julia_set_count()はこのアルゴリズムを実装しており、(-1.5, -1.5)から(1.5, 1.5)の領域をresolution * resolutionのグリッドに等分割し、2次元配列gridを使用して各グリッドに反復点が落ちた回数を保存します。関数の前にnumba.jitデコレータを使用すると、ジャストインタイムコンパイル後の関数を直接取得できます。
@nb.jit
def numba_julia_set_count(c, n, resolution=1000):
grid = np.zeros((resolution, resolution), np.int32)
z = 0 + 0j
for i in range(n):
z = cmath.sqrt(z - c)
if random.randint(0, 1):
z = -z
col = int((resolution * (z.real + 1.5) / 3.0))
row = int((resolution * (-z.imag + 1.5) / 3.0))
if 0 <= col < resolution and 0 <= row < resolution:
grid[row, col] += 1
return grid
ジャストインタイムコンパイル関数のpy_func属性を使用して、元のPython関数を取得できます。以下では、ジャストインタイムコンパイル前後の実行時間を比較します:
numba_julia_set_count(c, 10, 10)
%timeit numba_julia_set_count(c, 100000, 300)
%timeit numba_julia_set_count.py_func(c, 100000, 300)
4.84 ms ± 56.9 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
310 ms ± 13.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
反復アルゴリズムの改良#
ランダムに反復点を選択する方法は簡単に実装できますが、Julia集合の各位置を均等に探索するのは難しいです。より均等に反復を行うためには、2つの反復点の両方に対して反復計算を行い、あるグリッドに落ちた回数が閾値max_countを超えた場合、そのグリッド内の点に対して反復計算を行わないようにします。以下のnumba_julia_set_count_miim()はこの反復アルゴリズムを実装しています。プログラムでは、配列pをキューとして使用し、jは新しい反復点のインデックス、iは次に反復計算を行う点のインデックスです。j - iは反復待ちのキューの長さです。反復を開始する際、初期反復点をpのインデックス0に書き込み、この時点でキューの長さは1です。その後、ループ内でキューから1つの点を取り出して反復計算を行い、2つの点を取得します。反復点がgrid内の対応する回数が閾値未満の場合、その点をキューに追加し、grid内の対応するカウントを更新します。以下のいずれかの停止条件が真になるまでこのループを続けます:
キューの長さが0の場合、つまり
i == jの場合;反復点が
gridの対応する範囲を超えた場合;インデックス
jが配列pの長さに等しい場合、つまり配列pが満杯になった場合。
import numpy as np
@nb.jit
def numba_julia_set_count_miim(c, n, resolution=1000, max_count=10):
p = np.zeros(n, np.complex128)
grid = np.zeros((resolution, resolution), np.int32)
j = 1
i = 0
z = 0 + 0j
p[0] = z
while True:
if i >= j:
break
z = p[i]
i += 1
z = (z - c) ** 0.5
zr = z.real
zi = z.imag
if zr <= -2 or zr >= 2 or zi <= -2 or zi >= 2:
break
for k in range(2):
col = int((resolution * (z.real + 1.5) / 3.0))
row = int((resolution * (-z.imag + 1.5) / 3.0))
if 0 <= col < resolution and 0 <= row < resolution:
if grid[row, col] < max_count:
grid[row, col] += 1
p[j] = z
j += 1
if j == n:
return grid
z = -z
return grid
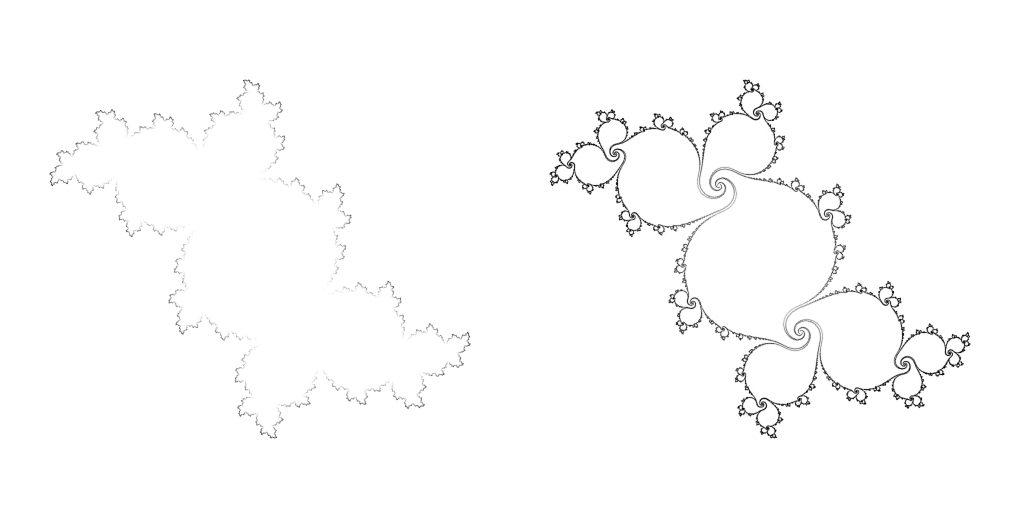
次のグラフでは、numba_julia_set_count()とnumba_julia_set_count_miim()の計算結果を比較しています。ランダム反復法の結果r_iimでは反復回数が不均一であるため、その対数を取ってから画像として表示しています。改良反復法(右)はランダム反復法(左)よりも多くの内部詳細を計算できることがわかります。
c = -0.11 + 0.65569999 * 1j
r_iim = numba_julia_set_count(c, 1000000)
r_miim = numba_julia_set_count_miim(c, 1000000)
fig, axes = plt.subplots(1, 2, figsize=(10, 6))
fig.subplots_adjust(0, 0, 1, 1, 0, 0)
axes[0].imshow(np.log10(r_iim + 1), cmap="gray_r")
axes[1].imshow(r_miim, cmap="gray_r")
for ax in axes:
ax.set_aspect("equal")
ax.axis("off")